工作流和代理¶
本指南回顾了代理系统中常见的模式。在描述这些系统时,区分“工作流”和“代理”是有帮助的。这种区别的一个很好的解释方式可以在 Anthropic 的 构建有效的代理 博客文章中找到:
工作流是通过预定义代码路径来协调 LLM 和工具的系统。 代理则是 LLM 动态地指导自身流程和工具使用,保持对完成任务方式的控制的系统。
以下是一种可视化这些差异的简单方式:
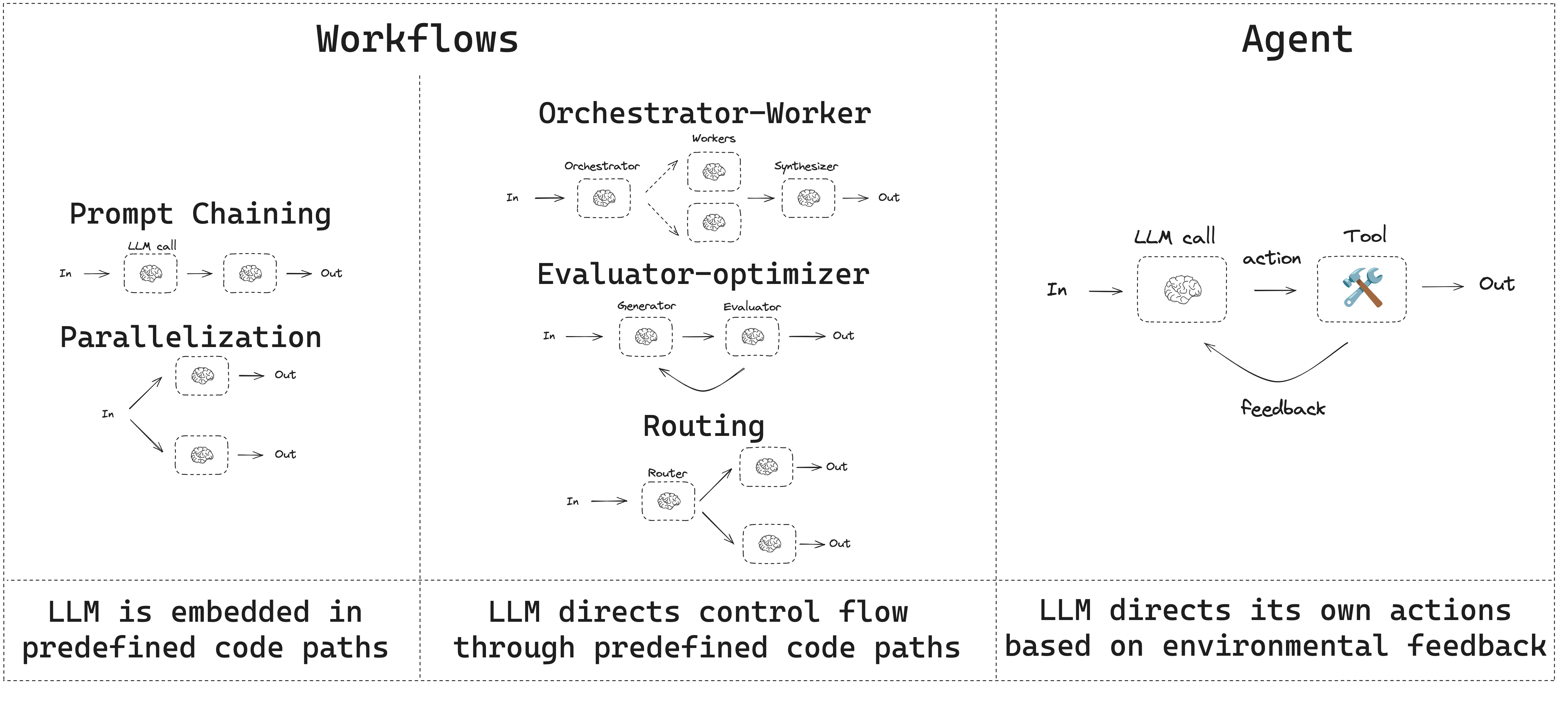
在构建代理和工作流时,LangGraph 提供了许多优势,包括持久性、流式传输以及对调试和部署的支持。
设置¶
你可以使用任何支持结构化输出和工具调用的聊天模型。下面,我们将展示安装包、设置 API 密钥以及测试 Anthropic 的结构化输出 / 工具调用的过程。
初始化一个 LLM
API Reference: ChatAnthropic
import os
import getpass
from langchain_anthropic import ChatAnthropic
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("ANTHROPIC_API_KEY")
llm = ChatAnthropic(model="claude-3-5-sonnet-latest")
构建模块:增强的 LLM¶
LLM 具有支持构建工作流和代理的增强功能。这些包括 结构化输出 和 工具调用,如下图所示,来自 Anthropic 博客的 Building Effective Agents:

# 结构化输出的 Schema
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
search_query: str = Field(None, description="优化的网络搜索查询。")
justification: str = Field(
None, description="此查询为何与用户的请求相关。"
)
# 使用结构化输出的 Schema 增强 LLM
structured_llm = llm.with_structured_output(SearchQuery)
# 调用增强的 LLM
output = structured_llm.invoke("Calcium CT 评分与高胆固醇有什么关系?")
# 定义一个工具
def multiply(a: int, b: int) -> int:
return a * b
# 使用工具增强 LLM
llm_with_tools = llm.bind_tools([multiply])
# 调用会触发工具调用的输入
msg = llm_with_tools.invoke("2 乘以 3 是多少?")
# 获取工具调用
msg.tool_calls
提示链¶
在提示链中,每个LLM调用都会处理前一个调用的输出。
如Anthropic博客《构建有效的代理》中所述:
提示链将任务分解为一系列步骤,其中每个LLM调用处理前一个调用的输出。您可以在任何中间步骤上添加程序检查(参见下图中的“gate”),以确保流程仍然保持正确方向。
使用此工作流的时机:当任务可以轻松且清晰地分解为固定子任务时,此工作流非常理想。主要目标是通过使每个LLM调用的任务更简单来权衡延迟和更高的准确性。

from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# 图状态
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# 节点
def generate_joke(state: State):
"""第一个LLM调用来生成初始笑话"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def check_punchline(state: State):
"""门函数,用于检查笑话是否有 punchline(笑点)"""
# 简单检查 - 笑话是否包含 "?" 或 "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""第二个LLM调用来改进笑话"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
def polish_joke(state: State):
"""第三个LLM调用进行最终润色"""
msg = llm.invoke(f"Add a surprising twist to this joke: {state['improved_joke']}")
return {"final_joke": msg.content}
# 构建工作流
workflow = StateGraph(State)
# 添加节点
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# 添加边来连接节点
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# 编译
chain = workflow.compile()
# 显示工作流
display(Image(chain.get_graph().draw_mermaid_png()))
# 调用
state = chain.invoke({"topic": "cats"})
print("Initial joke:")
print(state["joke"])
print("\n--- --- ---\n")
if "improved_joke" in state:
print("Improved joke:")
print(state["improved_joke"])
print("\n--- --- ---\n")
print("Final joke:")
print(state["final_joke"])
else:
print("Joke failed quality gate - no punchline detected!")
LangSmith Trace
https://smith.langchain.com/public/a0281fca-3a71-46de-beee-791468607b75/r
资源:
LangChain Academy
请查看我们关于提示链的课程 此处。
from langgraph.func import entrypoint, task
# 任务
@task
def generate_joke(topic: str):
"""第一个LLM调用来生成初始笑话"""
msg = llm.invoke(f"Write a short joke about {topic}")
return msg.content
def check_punchline(joke: str):
"""门函数,用于检查笑话是否有 punchline(笑点)"""
# 简单检查 - 笑话是否包含 "?" 或 "!"
if "?" in joke or "!" in joke:
return "Fail"
return "Pass"
@task
def improve_joke(joke: str):
"""第二个LLM调用来改进笑话"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {joke}")
return msg.content
@task
def polish_joke(joke: str):
"""第三个LLM调用进行最终润色"""
msg = llm.invoke(f"Add a surprising twist to this joke: {joke}")
return msg.content
@entrypoint()
def prompt_chaining_workflow(topic: str):
original_joke = generate_joke(topic).result()
if check_punchline(original_joke) == "Pass":
return original_joke
improved_joke = improve_joke(original_joke).result()
return polish_joke(improved_joke).result()
# 调用
for step in prompt_chaining_workflow.stream("cats", stream_mode="updates"):
print(step)
print("\n")
LangSmith Trace
https://smith.langchain.com/public/332fa4fc-b6ca-416e-baa3-161625e69163/r
并行化¶
通过并行化,大语言模型(LLMs)可以同时处理一个任务:
大语言模型有时可以同时处理一个任务,并且其输出可以通过编程方式聚合。这种工作流程,称为并行化,主要体现在两个关键变体中:分块(Sectioning):将任务分解为独立的子任务并行执行;投票(Voting):多次运行同一任务以获得多样化的输出。
何时使用此工作流程:当划分后的子任务可以并行执行以提高速度,或者需要多个视角或尝试以提高结果的可信度时,这种工作流程非常有效。对于需要多方面考虑的复杂任务,通常每个考虑由单独的大语言模型调用处理,可以让每个特定方面得到更集中的关注。

# 图状态
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# 节点
def call_llm_1(state: State):
"""第一次调用LLM生成初始笑话"""
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def call_llm_2(state: State):
"""第二次调用LLM生成故事"""
msg = llm.invoke(f"Write a story about {state['topic']}")
return {"story": msg.content}
def call_llm_3(state: State):
"""第三次调用LLM生成诗歌"""
msg = llm.invoke(f"Write a poem about {state['topic']}")
return {"poem": msg.content}
def aggregator(state: State):
"""将笑话和故事合并成一个输出"""
combined = f"Here's a story, joke, and poem about {state['topic']}!\n\n"
combined += f"STORY:\n{state['story']}\n\n"
combined += f"JOKE:\n{state['joke']}\n\n"
combined += f"POEM:\n{state['poem']}"
return {"combined_output": combined}
# 构建工作流
parallel_builder = StateGraph(State)
# 添加节点
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# 添加边连接节点
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# 显示工作流
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
# 调用
state = parallel_workflow.invoke({"topic": "cats"})
print(state["combined_output"])
LangSmith Trace
https://smith.langchain.com/public/3be2e53c-ca94-40dd-934f-82ff87fac277/r
资源:
文档
请参阅我们关于并行化的文档 这里.
LangChain 学院
请参阅我们关于并行化的课程 这里.
@task
def call_llm_1(topic: str):
"""第一次调用LLM生成初始笑话"""
msg = llm.invoke(f"Write a joke about {topic}")
return msg.content
@task
def call_llm_2(topic: str):
"""第二次调用LLM生成故事"""
msg = llm.invoke(f"Write a story about {topic}")
return msg.content
@task
def call_llm_3(topic):
"""第三次调用LLM生成诗歌"""
msg = llm.invoke(f"Write a poem about {topic}")
return msg.content
@task
def aggregator(topic, joke, story, poem):
"""将笑话和故事合并成一个输出"""
combined = f"Here's a story, joke, and poem about {topic}!\n\n"
combined += f"STORY:\n{story}\n\n"
combined += f"JOKE:\n{joke}\n\n"
combined += f"POEM:\n{poem}"
return combined
# 构建工作流
@entrypoint()
def parallel_workflow(topic: str):
joke_fut = call_llm_1(topic)
story_fut = call_llm_2(topic)
poem_fut = call_llm_3(topic)
return aggregator(
topic, joke_fut.result(), story_fut.result(), poem_fut.result()
).result()
# 调用
for step in parallel_workflow.stream("cats", stream_mode="updates"):
print(step)
print("\n")
LangSmith Trace
https://smith.langchain.com/public/623d033f-e814-41e9-80b1-75e6abb67801/r
路由¶
路由对输入进行分类,并将其导向后续任务。如Anthropic博客中关于构建有效的代理(Agents)所述:
路由对输入进行分类,并将其导向专门的后续任务。这种工作流程允许分离关注点,构建更专业的提示。没有这种工作流程,优化一种类型的输入可能会损害其他输入的表现。
何时使用此工作流程:路由适用于复杂任务,其中存在更好分开处理的不同类别,且分类可以准确地通过LLM或更传统的分类模型/算法来完成。

from typing_extensions import Literal
from langchain_core.messages import HumanMessage, SystemMessage
# 用于路由逻辑的结构化输出模式
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="路由过程中的下一步"
)
# 使用结构化输出模式增强LLM
router = llm.with_structured_output(Route)
# 状态
class State(TypedDict):
input: str
decision: str
output: str
# 节点
def llm_call_1(state: State):
"""写一个故事"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_2(state: State):
"""讲个笑话"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_3(state: State):
"""写一首诗"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_router(state: State):
"""将输入路由到适当的节点"""
# 运行增强后的LLM以结构化输出作为路由逻辑
decision = router.invoke(
[
SystemMessage(
content="根据用户的请求,将输入路由到故事、笑话或诗歌。"
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# 条件边函数,用于路由到适当的节点
def route_decision(state: State):
# 返回你希望访问的下一个节点名称
if state["decision"] == "story":
return "llm_call_1"
elif state["decision"] == "joke":
return "llm_call_2"
elif state["decision"] == "poem":
return "llm_call_3"
# 构建工作流
router_builder = StateGraph(State)
# 添加节点
router_builder.add_node("llm_call_1", llm_call_1)
router_builder.add_node("llm_call_2", llm_call_2)
router_builder.add_node("llm_call_3", llm_call_3)
router_builder.add_node("llm_call_router", llm_call_router)
# 添加边连接节点
router_builder.add_edge(START, "llm_call_router")
router_builder.add_conditional_edges(
"llm_call_router",
route_decision,
{ # 由route_decision返回的名称 : 下一步要访问的节点名称
"llm_call_1": "llm_call_1",
"llm_call_2": "llm_call_2",
"llm_call_3": "llm_call_3",
},
)
router_builder.add_edge("llm_call_1", END)
router_builder.add_edge("llm_call_2", END)
router_builder.add_edge("llm_call_3", END)
# 编译工作流
router_workflow = router_builder.compile()
# 显示工作流
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# 调用
state = router_workflow.invoke({"input": "给我讲个关于猫的笑话"})
print(state["output"])
LangSmith 跟踪
https://smith.langchain.com/public/c4580b74-fe91-47e4-96fe-7fac598d509c/r
资源:
LangChain 学院
请查看我们关于路由的课程 here。
示例
from typing_extensions import Literal
from pydantic import BaseModel
from langchain_core.messages import HumanMessage, SystemMessage
# 用于路由逻辑的结构化输出模式
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="路由过程中的下一步"
)
# 使用结构化输出模式增强LLM
router = llm.with_structured_output(Route)
@task
def llm_call_1(input_: str):
"""写一个故事"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_2(input_: str):
"""讲个笑话"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_3(input_: str):
"""写一首诗"""
result = llm.invoke(input_)
return result.content
def llm_call_router(input_: str):
"""将输入路由到适当的节点"""
# 运行增强后的LLM以结构化输出作为路由逻辑
decision = router.invoke(
[
SystemMessage(
content="根据用户的请求,将输入路由到故事、笑话或诗歌。"
),
HumanMessage(content=input_),
]
)
return decision.step
# 创建工作流
@entrypoint()
def router_workflow(input_: str):
next_step = llm_call_router(input_)
if next_step == "story":
llm_call = llm_call_1
elif next_step == "joke":
llm_call = llm_call_2
elif next_step == "poem":
llm_call = llm_call_3
return llm_call(input_).result()
# 调用
for step in router_workflow.stream("Write me a joke about cats", stream_mode="updates"):
print(step)
print("\n")
LangSmith 跟踪
https://smith.langchain.com/public/5e2eb979-82dd-402c-b1a0-a8cceaf2a28a/r
Orchestrator-Worker¶
通过使用 orchestrator-worker,一个 orchestrator 可以将任务分解并委托给 workers 执行每个子任务。如 Anthropic 博客中提到的 Building Effective Agents:
在 orchestrator-workers 工作流中,一个中心化的 LLM 动态地分解任务,将其委托给 worker LLMs,并合成它们的结果。
使用此工作流的时机:该工作流适用于那些无法预测所需子任务的复杂任务(例如,在编程中,需要更改的文件数量以及每个文件更改的性质可能取决于任务)。虽然它在拓扑结构上与并行化类似,但其关键区别在于灵活性——子任务不是预先定义好的,而是由 orchestrator 根据特定输入来确定的。

from typing import Annotated, List
import operator
# 用于规划的结构化输出模式
class Section(BaseModel):
name: str = Field(
description="报告本部分的名称。",
)
description: str = Field(
description="本部分将涵盖的主要主题和概念的简要概述。",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="报告的各个部分。",
)
# 为 LLM 增加结构化输出模式
planner = llm.with_structured_output(Sections)
在 LangGraph 中创建 Workers
因为 orchestrator-worker 工作流很常见,LangGraph 提供了 Send API 来支持这一功能。它允许你动态创建 worker 节点并将特定输入发送给每一个节点。每个 worker 都有自己的状态,所有 worker 的输出都写入一个 共享状态键,这个键对 orchestrator 图是可访问的。这使 orchestrator 能够访问所有 worker 的输出,并将它们综合成最终的输出。如下所示,我们遍历一个 section 列表并 Send 每个 section 到 worker 节点。进一步文档请参见 这里 和 这里。
from langgraph.constants import Send
# 图状态
class State(TypedDict):
topic: str # 报告主题
sections: list[Section] # 报告的各个部分
completed_sections: Annotated[
list, operator.add
] # 所有 worker 都写入此键进行并行操作
final_report: str # 最终报告
# Worker 状态
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
# 节点
def orchestrator(state: State):
"""生成报告计划的 orchestrator"""
# 生成查询
report_sections = planner.invoke(
[
SystemMessage(content="为报告生成一个计划。"),
HumanMessage(content=f"这里是报告主题: {state['topic']}"),
]
)
return {"sections": report_sections.sections}
def llm_call(state: WorkerState):
"""Worker 写出报告的一个部分"""
# 生成 section
section = llm.invoke(
[
SystemMessage(
content="按照提供的名称和描述撰写报告部分。每个部分不要前言。使用 markdown 格式。"
),
HumanMessage(
content=f"这里是 section 名称: {state['section'].name} 和描述: {state['section'].description}"
),
]
)
# 将更新后的 section 写入 completed sections
return {"completed_sections": [section.content]}
def synthesizer(state: State):
"""从各部分合成完整的报告"""
# 已完成的部分列表
completed_sections = state["completed_sections"]
# 将完成的部分格式化为字符串,作为最终部分的上下文
completed_report_sections = "\n\n---\n\n".join(completed_sections)
return {"final_report": completed_report_sections}
# 条件边函数,创建每个写入报告部分的 llm_call worker
def assign_workers(state: State):
"""为计划中的每个 section 分配一个 worker"""
# 通过 Send() API 并行启动 section 写入
return [Send("llm_call", {"section": s}) for s in state["sections"]]
# 构建工作流
orchestrator_worker_builder = StateGraph(State)
# 添加节点
orchestrator_worker_builder.add_node("orchestrator", orchestrator)
orchestrator_worker_builder.add_node("llm_call", llm_call)
orchestrator_worker_builder.add_node("synthesizer", synthesizer)
# 添加边连接节点
orchestrator_worker_builder.add_edge(START, "orchestrator")
orchestrator_worker_builder.add_conditional_edges(
"orchestrator", assign_workers, ["llm_call"]
)
orchestrator_worker_builder.add_edge("llm_call", "synthesizer")
orchestrator_worker_builder.add_edge("synthesizer", END)
# 编译工作流
orchestrator_worker = orchestrator_worker_builder.compile()
# 显示工作流
display(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
# 调用
state = orchestrator_worker.invoke({"topic": "创建关于 LLM 扩展定律的报告"})
from IPython.display import Markdown
Markdown(state["final_report"])
LangSmith Trace
https://smith.langchain.com/public/78cbcfc3-38bf-471d-b62a-b299b144237d/r
资源:
LangChain Academy
查看我们的关于 orchestrator-worker 的课程 这里。
示例
from typing import List
# 用于规划的结构化输出模式
class Section(BaseModel):
name: str = Field(
description="报告本部分的名称。",
)
description: str = Field(
description="本部分将涵盖的主要主题和概念的简要概述。",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="报告的各个部分。",
)
# 为 LLM 增加结构化输出模式
planner = llm.with_structured_output(Sections)
@task
def orchestrator(topic: str):
"""生成报告计划的 orchestrator"""
# 生成查询
report_sections = planner.invoke(
[
SystemMessage(content="为报告生成一个计划。"),
HumanMessage(content=f"这里是报告主题: {topic}"),
]
)
return report_sections.sections
@task
def llm_call(section: Section):
"""Worker 写出报告的一个部分"""
# 生成 section
result = llm.invoke(
[
SystemMessage(content="撰写报告部分。"),
HumanMessage(
content=f"这里是 section 名称: {section.name} 和描述: {section.description}"
),
]
)
# 将更新后的 section 写入 completed sections
return result.content
@task
def synthesizer(completed_sections: list[str]):
"""从各部分合成完整的报告"""
final_report = "\n\n---\n\n".join(completed_sections)
return final_report
@entrypoint()
def orchestrator_worker(topic: str):
sections = orchestrator(topic).result()
section_futures = [llm_call(section) for section in sections]
final_report = synthesizer(
[section_fut.result() for section_fut in section_futures]
).result()
return final_report
# 调用
report = orchestrator_worker.invoke("创建关于 LLM 扩展定律的报告")
from IPython.display import Markdown
Markdown(report)
LangSmith Trace
https://smith.langchain.com/public/75a636d0-6179-4a12-9836-e0aa571e87c5/r
Evaluator-optimizer¶
在 evaluator-optimizer 工作流中,一个 LLM 调用生成响应,另一个则在循环中提供评估和反馈:
在 evaluator-optimizer 工作流中,一个 LLM 调用生成响应,另一个则在循环中提供评估和反馈。
使用此工作流的时机:当拥有明确的评估标准时,且迭代优化能带来可衡量的价值时,该工作流特别有效。良好的匹配有两个标志:首先,当人类表达反馈时,LLM 响应可以明显改进;其次,LLM 能够提供此类反馈。这类似于人类作者在撰写一份完善文档时可能经历的迭代写作过程。

# Graph state
class State(TypedDict):
joke: str
topic: str
feedback: str
funny_or_not: str
# Schema for structured output to use in evaluation
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="Decide if the joke is funny or not.",
)
feedback: str = Field(
description="If the joke is not funny, provide feedback on how to improve it.",
)
# Augment the LLM with schema for structured output
evaluator = llm.with_structured_output(Feedback)
# Nodes
def llm_call_generator(state: State):
"""LLM generates a joke"""
if state.get("feedback"):
msg = llm.invoke(
f"Write a joke about {state['topic']} but take into account the feedback: {state['feedback']}"
)
else:
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def llm_call_evaluator(state: State):
"""LLM evaluates the joke"""
grade = evaluator.invoke(f"Grade the joke {state['joke']}")
return {"funny_or_not": grade.grade, "feedback": grade.feedback}
# Conditional edge function to route back to joke generator or end based upon feedback from the evaluator
def route_joke(state: State):
"""Route back to joke generator or end based upon feedback from the evaluator"""
if state["funny_or_not"] == "funny":
return "Accepted"
elif state["funny_or_not"] == "not funny":
return "Rejected + Feedback"
# Build workflow
optimizer_builder = StateGraph(State)
# Add the nodes
optimizer_builder.add_node("llm_call_generator", llm_call_generator)
optimizer_builder.add_node("llm_call_evaluator", llm_call_evaluator)
# Add edges to connect nodes
optimizer_builder.add_edge(START, "llm_call_generator")
optimizer_builder.add_edge("llm_call_generator", "llm_call_evaluator")
optimizer_builder.add_conditional_edges(
"llm_call_evaluator",
route_joke,
{ # Name returned by route_joke : Name of next node to visit
"Accepted": END,
"Rejected + Feedback": "llm_call_generator",
},
)
# Compile the workflow
optimizer_workflow = optimizer_builder.compile()
# Show the workflow
display(Image(optimizer_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = optimizer_workflow.invoke({"topic": "Cats"})
print(state["joke"])
LangSmith Trace
https://smith.langchain.com/public/86ab3e60-2000-4bff-b988-9b89a3269789/r
Resources:
Examples
# Schema for structured output to use in evaluation
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="Decide if the joke is funny or not.",
)
feedback: str = Field(
description="If the joke is not funny, provide feedback on how to improve it.",
)
# Augment the LLM with schema for structured output
evaluator = llm.with_structured_output(Feedback)
# Nodes
@task
def llm_call_generator(topic: str, feedback: Feedback):
"""LLM generates a joke"""
if feedback:
msg = llm.invoke(
f"Write a joke about {topic} but take into account the feedback: {feedback}"
)
else:
msg = llm.invoke(f"Write a joke about {topic}")
return msg.content
@task
def llm_call_evaluator(joke: str):
"""LLM evaluates the joke"""
feedback = evaluator.invoke(f"Grade the joke {joke}")
return feedback
@entrypoint()
def optimizer_workflow(topic: str):
feedback = None
while True:
joke = llm_call_generator(topic, feedback).result()
feedback = llm_call_evaluator(joke).result()
if feedback.grade == "funny":
break
return joke
# Invoke
for step in optimizer_workflow.stream("Cats", stream_mode="updates"):
print(step)
print("\n")
LangSmith Trace
https://smith.langchain.com/public/f66830be-4339-4a6b-8a93-389ce5ae27b4/r
Agent¶
代理通常实现为一个LLM,在循环中基于环境反馈执行操作(通过工具调用)。如Anthropic博客《Building Effective Agents》中所述:
代理可以处理复杂的任务,但它们的实现通常是直接的。它们通常只是基于环境反馈在循环中使用工具的LLM。因此,设计工具集及其文档时必须清晰且深思熟虑。
使用代理的时机:当问题具有开放性,难以或不可能预测所需步骤数量,或者你无法硬编码固定路径时,可以使用代理。LLM可能需要进行多次操作,因此你必须对其决策有一定的信任。代理的自主性使它们非常适合在可信环境中扩展任务。

API Reference: tool
from langchain_core.tools import tool
# 定义工具
@tool
def multiply(a: int, b: int) -> int:
"""将a和b相乘。
Args:
a: 第一个整数
b: 第二个整数
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""将a和b相加。
Args:
a: 第一个整数
b: 第二个整数
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""将a除以b。
Args:
a: 第一个整数
b: 第二个整数
"""
return a / b
# 将工具添加到LLM
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage
# 节点
def llm_call(state: MessagesState):
"""LLM决定是否调用工具"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="你是一个有帮助的助手,负责对一组输入执行算术运算。"
)
]
+ state["messages"]
)
]
}
def tool_node(state: dict):
"""执行工具调用"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# 条件边函数,根据LLM是否进行了工具调用来路由到工具节点或结束
def should_continue(state: MessagesState) -> Literal["environment", END]:
"""根据LLM是否进行了工具调用来决定是继续循环还是停止"""
messages = state["messages"]
last_message = messages[-1]
# 如果LLM进行了工具调用,则执行一个动作
if last_message.tool_calls:
return "Action"
# 否则,我们停止(回复用户)
return END
# 构建工作流
agent_builder = StateGraph(MessagesState)
# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("environment", tool_node)
# 添加边来连接节点
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
# should_continue返回的名称 : 下一步要访问的节点名称
"Action": "environment",
END: END,
},
)
agent_builder.add_edge("environment", "llm_call")
# 编译代理
agent = agent_builder.compile()
# 显示代理
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# 调用
messages = [HumanMessage(content="将3和4相加。")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
LangSmith Trace
https://smith.langchain.com/public/051f0391-6761-4f8c-a53b-22231b016690/r
资源:
LangChain Academy
看看我们关于代理的课程 这里。
示例
这里 是一个使用工具调用代理创建/存储长期记忆的项目。
from langgraph.graph import add_messages
from langchain_core.messages import (
SystemMessage,
HumanMessage,
BaseMessage,
ToolCall,
)
@task
def call_llm(messages: list[BaseMessage]):
"""LLM决定是否调用工具"""
return llm_with_tools.invoke(
[
SystemMessage(
content="你是一个有帮助的助手,负责对一组输入执行算术运算。"
)
]
+ messages
)
@task
def call_tool(tool_call: ToolCall):
"""执行工具调用"""
tool = tools_by_name[tool_call["name"]]
return tool.invoke(tool_call)
@entrypoint()
def agent(messages: list[BaseMessage]):
llm_response = call_llm(messages).result()
while True:
if not llm_response.tool_calls:
break
# 执行工具
tool_result_futures = [
call_tool(tool_call) for tool_call in llm_response.tool_calls
]
tool_results = [fut.result() for fut in tool_result_futures]
messages = add_messages(messages, [llm_response, *tool_results])
llm_response = call_llm(messages).result()
messages = add_messages(messages, llm_response)
return messages
# 调用
messages = [HumanMessage(content="将3和4相加。")]
for chunk in agent.stream(messages, stream_mode="updates"):
print(chunk)
print("\n")
LangSmith Trace
https://smith.langchain.com/public/42ae8bf9-3935-4504-a081-8ddbcbfc8b2e/r
Pre-built¶
LangGraph还提供了一个**预构建方法**,用于创建上述定义的代理(使用 create_react_agent 函数):
https://langchain-ai.github.io/langgraph/how-tos/create-react-agent/
API Reference: create_react_agent
from langgraph.prebuilt import create_react_agent
# 传入:
# (1) 带有工具的增强LLM
# (2) 工具列表(用于创建工具节点)
pre_built_agent = create_react_agent(llm, tools=tools)
# 显示代理
display(Image(pre_built_agent.get_graph().draw_mermaid_png()))
# 调用
messages = [HumanMessage(content="将3和4相加。")]
messages = pre_built_agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
LangSmith Trace
https://smith.langchain.com/public/abab6a44-29f6-4b97-8164-af77413e494d/r
LangGraph 提供的功能¶
通过在 LangGraph 中构建上述内容,我们可以获得以下功能:
持久化:人工干预(Human-in-the-Loop)¶
LangGraph 的持久化层支持对操作进行中断和批准(例如人工干预)。详见 LangChain Academy 的第 3 模块。
持久化:记忆¶
LangGraph 的持久化层支持对话(短期)记忆和长期记忆。详见 LangChain Academy 的第 2 模块 和 第 5 模块:
流式传输¶
LangGraph 提供了多种方式来流式传输工作流/代理的输出或中间状态。详见 LangChain Academy 的第 3 模块。
部署¶
LangGraph 提供了一种易于上手的部署、可观测性和评估方式。详见 LangChain Academy 的第 6 模块。